

Part 1: Dynamic SQL
with SEGs complete RUNSTATS Rescue package:
Why it is a good idea but why it fails in certain cases?
The story
What really happened?
How to fix the problem?
Rescue Steps
An example (with JCL panels)
Next Month
The story
This month I want to tell you a story. This story is true, but the names have been changed to protect the innocent!
A big company regularly scheduled production staging on Thursday nights. One night last year everything went as normal – until the Friday morning…
The problem quickly escalated from the standard “Help desk”-level answers of “Switch it off and on, reboot”, and “Have you changed anything?” to senior managers demanding to know why things were not working anymore.
At this point, the DBA group was not actually involved, as it was first thought that a “bad” package had been promoted “by accident” on the night before.
- The production group backed out the staged packages, but it didn’t help…
- The delays got worse. They then stopped nearly all of the WebSphere Servers to at least allow *some* work through the over loaded system. Now in full panic mode, the DBA and the JAVA teams got involved.They both quickly found the “culprit”, which was an extremely large and complex dynamic SQL statement that had worked fine until some time Thursday night, and was now behaving *very* badly indeed.
- The DBA team REORGed the “big” tables involved, in the hope that it would then all get better…
It didn’t. - Finally the DBA team proposed creating a new index which was quickly done and RUNSTATed in production.
The SQL then switched the access path back to a good one.
The WebSphere servers were all re-started, and gradually everything returned to normal.
This whole process actually took two days!
The company involved relies upon its logistics chains and Just-In-Time delivery, so this outage had some serious repercussions, of course… Get the full story
What really happened?
The DBA team then investigated further and found out that what had really happened, was that a RUNSTATS, on just one small table, had been run on the Thursday night at “an inappropriate time” thus causing the statement’s access path to go “pear-shaped”(aka Belly Up) all day Friday and half of Saturday…
How to fix the problem quickly and easily?
The DBA team then thought about ways that such a problem – should it reoccur in the future – could be quickly and easily fixed. Now my part of the story begins…
This company uses our software and had a license to run the Enterprise Statistics Distribution (ESD) component of Bind ImpactExpert, which extracts, and optionally converts, all of the DB2 Catalog data that the DB2 Optimizer needs to do its job. Normally, customers use this to copy all the production statistics over to a sand box style system, to see if a DB2 APAR or DB2 Migration will cause unforeseen problems. For this, they use the Early-PreCheck component of our tool Bind ImpactExpert for Dynamic or Static SQL. Now we do have another scenario, called DSC (Dynamic Statement Cache) Protection, that would nearly do what they wanted, but also does a lot more and, of course, costs more to use!
And so arose the idea for our new PocketTool called RUNSTATS Rescue. “Why is it a PocketTool?” I hear you ask “Because it only costs pocket money!” (aka Pin Money in the USA or an “allowance” if you prefer) These tools are inexpensive to use – really!
Now, before you stop reading at this point and start complaining about the fact this Newsletter is just 100% Marketing, please bear in mind that what I describe here could also be written by you – then you just need to give me credit for sharing the idea…
RUNSTATS Rescue
The idea is to use EXPLAIN in any way, shape or form, either in SPUFI, or directly in any monitor, to simply EXPLAIN the “culprit” SQL, and to remember the PLAN_TABLE owner you are using, as well as the QUERYNO you just used.
Using these two inputs, RUNSTATS Rescue analyses the EXPLAIN output to build a list of extract and update control cards for our ESD, for all of the tables used and *all* of the indexes – even those *not* used, of course! Finally a DSC flush RUNSTATS is also generated for all Tablespaces involved in the query to make sure that the next time this “culprit” SQL comes into the system, it will then use the correct statistics.
Now, of course, the question is: “How do I know which statistics to use as the Rescue statistics?”
The answer: “The ones that were there before you did a REORG with inline RUNSTATS or a stand-alone RUNSTATS”. This is the key point to bear in mind: You must simply run the ESD extract before any normal DB2 Database maintenance jobs run.
Most shops have days, or weekends, when they run these, and it is not a problem to extract the data and then copy it, for example, to a GENGROUP, to enable easily finding the date and time of the last extract when the statistics were “good”, thus enabling the RUNSTATS Rescue job to revert the required statistics very quickly. This gives the DBA group much-needed time to find out what really happened and take any appropriate action – almost – at their leisure.
10 Rescue Steps
- Select the new scenario RUNSTATS Rescue
- Generate some JCL
- Optionally copy to a GENGROUP dataset
- Insert the EXPLAIN TABLE-CREATOR and QUERYNO
- Automatic launch of our catalog browser
- Drill down to the Index level
- Ask “new” file name for the extracted “rescue” statistics
- Perform the RUNSTATS Rescue extraction
- Reset the statistics and executes the RUNSTATS
- The “Rescued” Statistics
Here’s a walkthrough example of how it looks in real life:
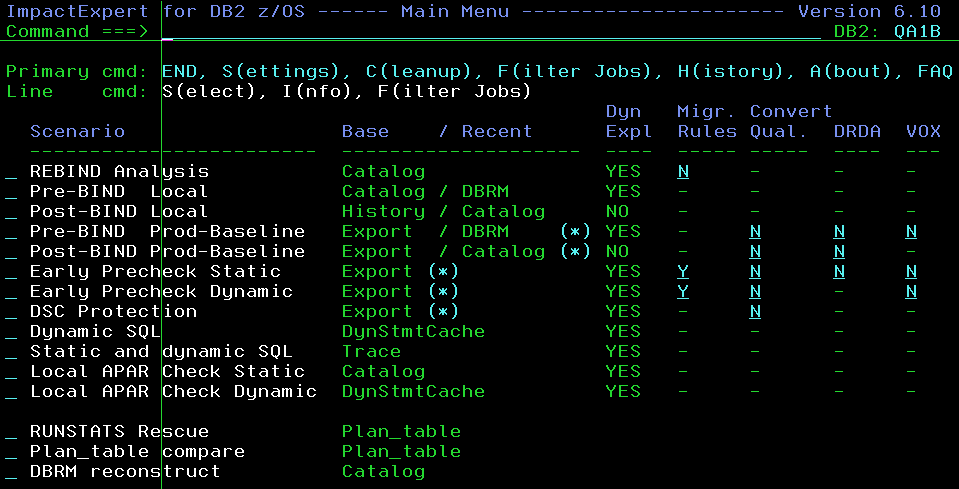
Near the bottom, you can see the new scenario RUNSTATS Rescue – select it to get a little pop-up window with the three steps. The first step must only be done once and then simply be plugged into an existing production job. I would recommend the first job of the normal DB2 Database Maintenance job stream.
1 – Select the new scenario RUNSTATS Rescue in the little pop-up window with the three steps
2 – Generate some JCL
The first option just generates some JCL looking like:

3 – Optionally copy to a GENGROUP dataset
At the end the optional step to copy to a GENGROUP dataset
4 – Insert the EXPLAIN TABLE-CREATOR and QUERYNO
Selecting the second option then requests the required input data as discussed earlier

5 – Automatic launch of our catalog browser
Hitting “enter” then launches our catalog browser to enable you to see which objects were being used by that SQL…
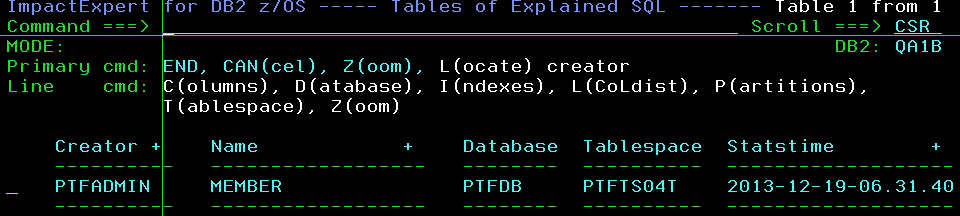
6 – Drill down to the Index Level
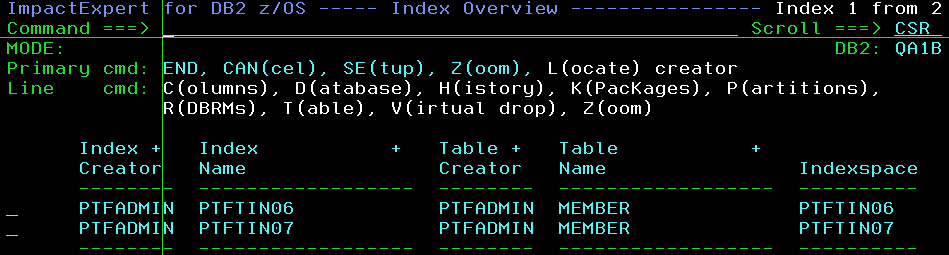
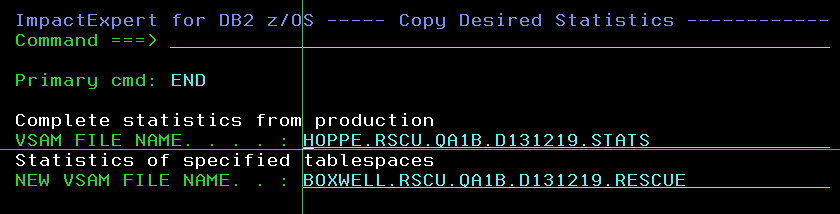
7 – Ask “new” file name for the extracted “rescue” statistics
PF3-ing out of the tool then asks for your original Production Statistics datasets, as extracted by the job in the first step, and a “new” file name for the extracted “rescue” statistics:
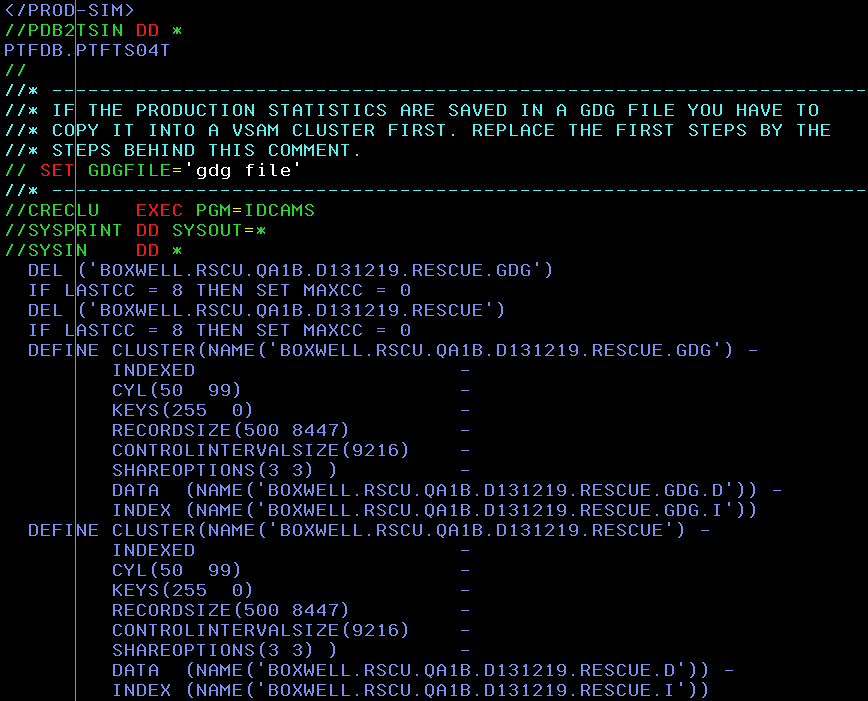
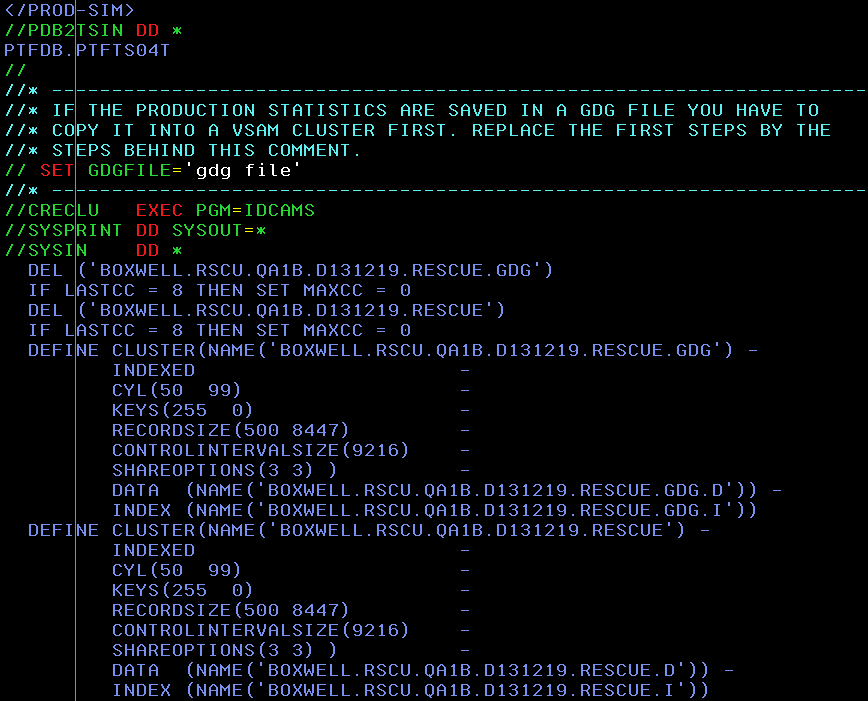
8 – Perform the RUNSTATS Rescue extraction
The next JCL appears that performs the RUNSTATS Rescue extraction, including the optional steps for GENGROUP support, as seen here:
9 – Reset the statistics and executes the RUNSTATS
Finally, the third option is selected, which actually resets the statistics and executes the RUNSTATS to flush the DSC
10 – The “Rescued” Statistics
Now the next time that statement appears, it will use the “rescued” statistics and get back its old Access Path.
Next Month
Next month I wish to expand upon this topic with the capability of doing the same for Static SQL.
The month after that, I will go into detail about the DSC Protection scenario I mentioned earlier. That is not a pocket tool, of course, but it *is* very interesting!
As usual any questions or comments are welcome,
TTFN Roy Boxwell
Senior Software Architect