This month, I must thank one of my readers who simply asked, “Roy, can you do a newsletter about the Shared Communications Area (SCA) for me please?” Naturally, I replied (after getting two beers from him of course!) So now I wish to delve into the inner workings of the Coupling Facility (CF) and the SCA…
Warning: Scary Stuff Ahead!
In a non-datasharing world, a -DISPLAY GROUP shows this sort of output:
DSN7100I -DD10 DSN7GCMD *** BEGIN DISPLAY OF GROUP(........) CATALOG LEVEL(V13R1M504) CURRENT FUNCTION LEVEL(V13R1M504) HIGHEST ACTIVATED FUNCTION LEVEL(V13R1M504) HIGHEST POSSIBLE FUNCTION LEVEL(V13R1M504) PROTOCOL LEVEL(2) GROUP ATTACH NAME(....) --------------------------------------------------------------------- DB2 SUB DB2 SYSTEM IRLM MEMBER ID SYS CMDPREF STATUS LVL NAME SUBSYS IRLMPROC -------- --- ---- -------- -------- ------ -------- ---- -------- ........ 0 DD10 -DD10 ACTIVE 131504 S0W1 IDD1 DD10IRLM --------------------------------------------------------------------- SPT01 INLINE LENGTH: 32138 *** END DISPLAY OF GROUP(........) DSN9022I -DD10 DSN7GCMD 'DISPLAY GROUP ' NORMAL COMPLETION
If that is what you see in your production system, dear reader, then this newsletter is, sadly, not for you!
Hopefully your output actually looks like my little test system:
DSN7100I -SD10 DSN7GCMD *** BEGIN DISPLAY OF GROUP(GSD10C11) CATALOG LEVEL(V13R1M504) CURRENT FUNCTION LEVEL(V13R1M504) HIGHEST ACTIVATED FUNCTION LEVEL(V13R1M504) HIGHEST POSSIBLE FUNCTION LEVEL(V13R1M504) PROTOCOL LEVEL(2) GROUP ATTACH NAME(SD1 ) --------------------------------------------------------------------- DB2 SUB DB2 SYSTEM IRLM MEMBER ID SYS CMDPREF STATUS LVL NAME SUBSYS IRLMPROC -------- --- ---- -------- -------- ------ -------- ---- -------- MEMSD10 1 SD10 -SD10 ACTIVE 131504 S0W1 JD10 SD10IRLM MEMSD11 2 SD11 -SD11 ACTIVE 131504 S0W1 JD11 SD11IRLM --------------------------------------------------------------------- SCA STRUCTURE SIZE: 16384 KB, STATUS= AC, SCA IN USE: 3 % LOCK1 STRUCTURE SIZE: 16384 KB NUMBER LOCK ENTRIES: 4194304 NUMBER LIST ENTRIES: 16354, LIST ENTRIES IN USE: 81 SPT01 INLINE LENGTH: 32138 *** END DISPLAY OF GROUP(GSD10C11) DSN9022I -SD10 DSN7GCMD 'DISPLAY GROUP ' NORMAL COMPLETION
The interesting stuff is from the “SCA STRUCTURE SIZE:” line down to the “NUMBER LIST ENTRIES:” line.
Off We Go!
To understand what an SCA is, we need to backtrack a second and first discuss what a CF is?
What is Inside?
The Coupling Facility is de facto *the* central part of data sharing, it contains three objects:
- A lock structure called LOCK1, where all the table locks using hashes live, and Record Lock Elements (RLE),
- A list structure that is actually the SCA, which contains a bunch of stuff I will go into later,
- The Group Buffer pools. Technically, you can run without these but then why are you data sharing if you are not sharing data?
Lock Structure Details
It is called LOCK1 and the system lock manager (SLM) uses the lock structure to control shared Db2 resources like tablespaces and pages and can enable concurrent access to these. It is split internally into two parts: The first part is the Lock Table Entry (LTE), and the second part is a list of update locks normally actually called the Record List Entry (RLE). The default is a 50:50 split of memory. The size of this structure must be big enough to avoid hash contention, which can be a major performance problem. Do not forget that the IRLM reserves 10% of the RLEs for “must complete” processes so you never actually get to use them all!
List Structure Details
This is really the SCA and it contains Member names, BSDS names, Data Base Exception Table (DBET) statuses and recovery information. Typically, at installation time, you pick a number for the INITSIZE (first allocated size of the SCA) from a list of 16 MB , 32 MB, 64 MB or 128 MB. Each of these INITSIZEs then has a SIZE which is typically twice the INITSIZE size as a maximum limit.
Baboom!
IBM write quite happily “Running out of SCA space can cause Db2 to fail” – I can change that to “does” not “can”!
Double Trouble?
The LOCK1 and the SCA do *not* have to be duplexed but it is very highly recommended to do so, otherwise, you have a single point of failure which defeats the whole point of going data sharing, really.
Death by DBET
The DBET data is, strangely enough, the thing that can easily kill ya!
How So?
Imagine you have the brilliant idea of using COPY YES indexes as you have tested a few and seen that RECOVER INDEX is quicker, better, faster than REBUILD or DROP/CREATE for the critical indexes at your shop.
What Happened Next?
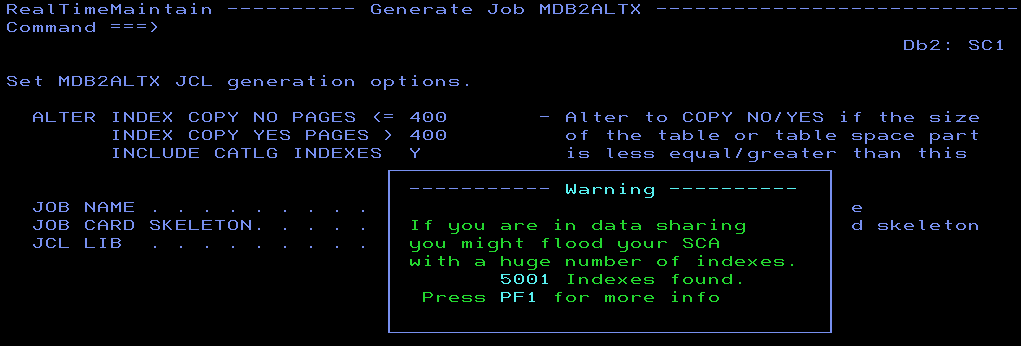
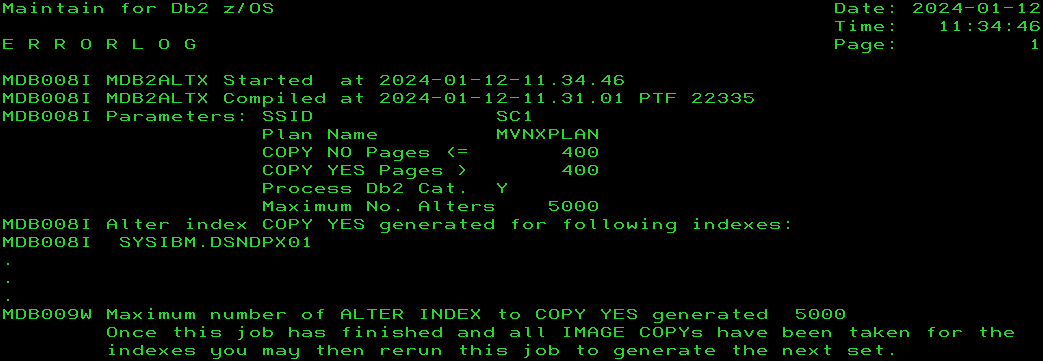
So how do you enable COPY YES at the index level? Just a simple ALTER INDEX xxx.yyy COPY YES is all it takes. But *what*, dear friends, does this ALTER do under the covers? It sets the INDEX to ICOPY status – “Not too bad”, you say as the index is fully available, “just wait until the next COPY and that status is then cleared” – But wait, that is a DBET status! It creates a DBET entry in your SCA… What if you alter 15,000 Indexes to all be COPY YES? Yep – Kiss goodbye to your Db2 sub-system!
Suicide Protection
Some software out there (RealTimeDBAExpert from SEGUS for example!) actually warns you about this and recommends you do this sort of thing in chunks. First the ALTER, then the COPY, one hundred blocks at a time and then the next batch etc.
and then if you do press PF1:
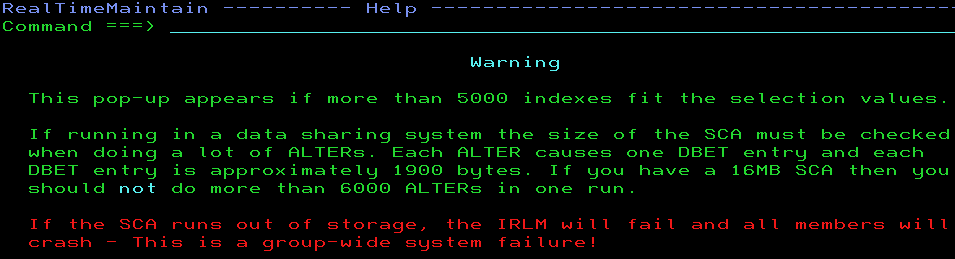
And even then, we have an emergency stop built-in that you can still override but then you must *know* the possible risk involved:
On the other hand, some software is like using SDSF DA when you put a P for “print” by your userid!
Now you know what *not* to do!
Automagic?
Use of the ALLOWAUTOALT(YES) has been discussed for years… on the one hand it automagically adds storage if you are running out, which is a good thing, *but* it also allows other competing systems to decrease storage which can then lead to you running out of storage and losing this Db2 sub-system… nasty, nasty!
Operator command time!
/f <yourirlm>,STATUS,STOR
Gives me:
DXR100I JD11002 STOR STATS PC: YES LTEW: 2 LTE: 4M RLE: 16354 RLEUSE: 18 BB PVT: 1266M AB PVT (MEMLIMIT): 2160M CSA USE: ACNT: 0K AHWM: 0K CUR: 2541K HWM: 6122K ABOVE 16M: 64 2541K BELOW 16M: 0 0K AB CUR: 0K AB HWM: 0K PVT USE: BB CUR: 5684K AB CUR: 5M BB HWM: 18M AB HWM: 5M CLASS TYPE SEGS MEM TYPE SEGS MEM TYPE SEGS MEM ACCNT T-1 2 4M T-2 1 1M T-3 2 8K PROC WRK 14 70K SRB 5 5K OTH 4 4K MISC VAR 41 7549K N-V 22 565K FIX 1 24K
This maps pretty nicely to the – DISPLAY GROUP I just did again:
*** BEGIN DISPLAY OF GROUP(GSD10C11) CATALOG LEVEL(V13R1M504) CURRENT FUNCTION LEVEL(V13R1M504) HIGHEST ACTIVATED FUNCTION LEVEL(V13R1M504) HIGHEST POSSIBLE FUNCTION LEVEL(V13R1M504) PROTOCOL LEVEL(2) GROUP ATTACH NAME(SD1 ) --------------------------------------------------------------------- DB2 SUB DB2 SYSTEM IRLM MEMBER ID SYS CMDPREF STATUS LVL NAME SUBSYS IRLMPROC -------- --- ---- -------- -------- ------ -------- ---- -------- MEMSD10 1 SD10 -SD10 ACTIVE 131504 S0W1 JD10 SD10IRLM MEMSD11 2 SD11 -SD11 ACTIVE 131504 S0W1 JD11 SD11IRLM --------------------------------------------------------------------- SCA STRUCTURE SIZE: 16384 KB, STATUS= AC, SCA IN USE: 3 % LOCK1 STRUCTURE SIZE: 16384 KB NUMBER LOCK ENTRIES: 4194304 NUMBER LIST ENTRIES: 16354, LIST ENTRIES IN USE: 18 SPT01 INLINE LENGTH: 32138 *** END DISPLAY OF GROUP(GSD10C11)
Looking at this line in the Modify output:
PC: YES LTEW: 2 LTE: 4M RLE: 16354 RLEUSE: 18
I only have two members so my LTEW (LTE Width) is two bytes, LTE is 4M which is my NUMBER LOCK ENTRIES: 4194304 , RLE is 16354 which is my NUMBER LIST ENTRIES: 16354 and RLEUSE is 18 which is my LIST ENTRIES IN USE: 18. A perfect match – if only they had agreed on a naming convention! ! !
You can also see that my SCA STATUS is AC for ACTIVE and the SCA IN USE is a measly 3%, so no worries for me today!
Finally, you can see that we have 50:50 split as the SCA and the LOCK1 are the same size: 16 MB.
One more line of interest:
BB PVT: 1266M AB PVT (MEMLIMIT): 2160M
Here you can see the calculated MEMLIMIT for the IRLM, which for my test system is very low, but you should check that the number is good for your site as the range is now much bigger!
Panic Time?
I would start to get seriously sweaty if the SCA IN USE ever got near 70%.
And?
I would not use ALLOWAUTOALT(YES) and allocate 256MB or, if forced, I would go with INITSIZE 128 MB and SIZE 256 MB and then ALLOWAUTOALT(YES).
Lock it Down!
The Max Storage for locks is between 2,048 MB and 16,384 PB with a default of 2,160 MB that I have in the PVT (MEMLIMIT) output above.
Locks per table(space) (NUMLKTS) is 0 to 104,857,600 with a default of 2,000 in Db2 12 and 5,000 in Db2 13. If this number is exceeded then lock escalation takes place unless it is zero in which case there is no lock escalation. As IBM nicely put it “Do not set the value to 0, because it can cause the IRLM to experience storage shortages”.
Locks per user (NUMLKUS) is also from 0 to 104,857,600 with a default of 10,000 in Db2 12 and 20,000 in Db2 13. 0 means no limit. IBM do not recommend 0 or a large number here unless it is really required to run an application. Db2 assumes that each lock is approximately 540 bytes of memory. Here you can also drain your IRLM until it runs out of ACCOUNT T-1 storage space:
DXR175E xxxxxxxx IRLM IS UNABLE TO OBTAIN STORAGE – PVT
This is not a message you ever want to see on the master console! Just do the math on your locks and your memory size!
The Bachelor Problem – Fear of Commitment
You must get the developers to COMMIT or not use row-level locking everywhere.
SCA DBET Calculation
The lock size for each DBET entry is approximately 1,864 bytes from my tests in Db2 12 FL 510. How did I determine that, you ask?
What I did, was multiple ALTER INDEX aaa.bbb COPY YES SQLs until the “SCA in use” percentage changed from 4% to 5%, and then I kept doing ALTERs and DISPLAYs until the percentage changed from 5% to 6%. It took me exactly 90 ALTERs and with an SCA size of 16,384KB, that gives me a size of around 1,864 bytes per DBET entry. Use this as a Rule Of Thumb for your DBET inducing ALTERs! It gives me a hard limit of about 6,000 Alters.
I hope you found this little discourse into the world of the Coupling Facility and SCA useful!
TTFN,
Roy Boxwell