

This month, I am going to tell you a true story from our labs in Düsseldorf, where I learnt a few things about Db2 and how the Db2 Directory works…
What is it?
The Db2 Directory is the “shadow” catalog if you like. It is basically the machine-readable stuff that echoes what is in some of the Db2 Catalog tables that we all know and love and use nearly every day!
Whatya got?
Well, the Db2 Directory is the DSNDB01 database and, up until Db2 10, was completely hidden from view when looking at it with SQL. The VSAM datasets were there but you could not select from them – Pretty useless! My company, Software Engineering GmbH, actually wrote an assembler program to read the SYSLGRNX table and output the interesting data therein so that it could be used for image copy decisions etc. But, then IBM finally decided to open up the Db2 Directory to our prying eyes! (Sad footnote: They still output the LGRDBID and LGRPSID as CHAR(2) fields!!! Completely useless for joining of course – See my older blogs all about SYSLGRNX and doing the conversion to a correct SMALLINT way of doing it!
Tables, Tables, Tables
You actually do not have that much data available for use with it!
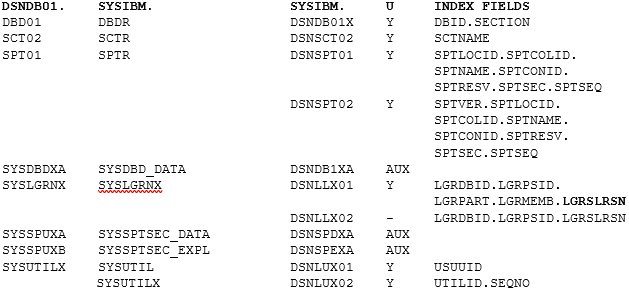
U is Unique index Y or – for Duplicates allowed and AUX for the standard LOB AUX Index. Bold field names are DESC order.
This table gives you an overview of what you get and also shows the two tablespaces that were, for me at least, of special interest!
Where’s the Beef?
On my test system, the tablespaces SYSSPUXA and SYSSPUXB were both getting larger and larger. Now the task is to understand why you need to know which of the above tables is “linked” to which other ones, and then which link to the Db2 Catalog tables. Time for another table!

So?
What you can see from this, is that the DSNDB01.SPT01 (which we know is the SYSIBM.SPTR) is linked to a whole bunch of Package-related tables and this is all documented – so far, so good! What got me interested, were the LOB tablespaces SYSSPUXA and SYSSPUXB. In my system they were taking up 13,929 and 6,357 Tracks respectively. Might not sound much to a real shop out there, but for me with only 118,000 rows in the SPTR it piqued my interest!
What is in it?
The SYSSPUXA (Table SYSSPTSEC_DATA) contains the machine-readable access paths generated by BIND/REBIND with versioning etc. so that being quite big was, sort of, OK. The SYSSPUXB (Table SYSSPTSEC_EXPL) contains *only* the EXPLAIN-related information for the access path. This was added a few Db2 releases ago so that you could extract the current access path without doing a REBIND EXPLAIN(YES) as that would show the access path “right now” as opposed to what it was, and still is, from, say, five years ago. These two access paths might well be completely different!
How many?
The SPTR had 6,630 tracks.
The SYSSPTSEC_DATA had 13,929 tracks.
The SYSSPTSEC_EXPL had 6,357 tracks.
This is a total of 1,795 Cylinders for 118,553 rows of data – for me, that’s a huge amount.
What is “in” there?
I quickly saw that there were *lots* of versions of packages and some very odd “ghosts” lurking in the data. Here’s a little query to give you a glimpse:
SELECT SUBSTR(SP.SPTCOLID, 1, 18) AS COLLID
, SUBSTR(SP.SPTNAME, 1, 8) AS NAME
, SUBSTR(SP.SPTVER, 1 , 26) AS VERSION
, HEX(SP.SPTRESV) AS RESERVED
FROM SYSIBM.SPTR SP
WHERE 1 = 1
-- AND NOT SP.SPTRESV = X'0000'
AND NOT SP.SPTCOLID LIKE 'DSN%'
AND NOT SP.SPTCOLID LIKE 'SYS%'
LIMIT 100
; Now, the weird thing is, that the SPTRESV (“RESERVED”) column obviously actually contains the Plan Management number. So, you have “normally” up to three entries. Zero for Original, One for Previous and Two for Current. What I saw, was a large number of Fours!
Set to Stun!
Where did they all come from? A quick bit of looking around revealed that it was Package Phase-In! They have to keep the old and the new executables somewhere… So then, I started trying to work out how to get rid of any old rubbish I had lying around.
FREE This!
First up was a simple FREE generator for old versions of programs deliberating excluding a few of our own packages that require versions for cross-system communications.
WITH NEWEST_PACKAGES (COLLID
,NAME
,CONTOKEN ) AS
(SELECT SP.SPTCOLID
,SP.SPTNAME
,MAX(SP.SPTCONID)
FROM SYSIBM.SPTR SP
WHERE NOT SP.SPTCOLID LIKE 'DSN%'
AND NOT SP.SPTCOLID LIKE 'SYS%'
AND NOT SP.SPTNAME IN ('IQADBACP' , 'IQAXPLN')
GROUP BY SP.SPTCOLID
,SP.SPTNAME
)
SELECT DISTINCT 'FREE PACKAGE(' CONCAT SQ.SPTCOLID
CONCAT '.' CONCAT SQ.SPTNAME
CONCAT '.(' CONCAT SQ.SPTVER
CONCAT '))'
FROM NEWEST_PACKAGES NP
,SYSIBM.SPTR SQ
,SYSIBM.SYSPACKAGE PK
WHERE NP.COLLID = SQ.SPTCOLID
AND NP.NAME = SQ.SPTNAME
AND NP.CONTOKEN > SQ.SPTCONID
AND SQ.SPTCOLID = PK.COLLID
AND SQ.SPTNAME = PK.NAME
AND PK.CONTOKEN > SQ.SPTCONID
AND PK.LASTUSED < CURRENT DATE - 180 DAYS
--LIMIT 100
; Note that this excludes all IBM packages and my two “SEGUS suspects” and pulls out all duplicates that have also not been executed for 180 days. Running it and then executing the generated FREEs got rid of a fair few, but those “Four” entries were all still there!
FREE What?
Then I found a nice new, well for me anyways, use of the FREE PACKAGE command. You have to be brave, you have to trust the documentation and you trust me because I have run it multiple times now! The syntax must be:
FREE PACKAGE(*.*.(*)) PLANMGMTSCOPE(PHASEOUT)
Do *not* forget that last part!!! Or make sure your resume is up to date!
This then gets rid of all the junk lying around! Was I finished? Of course not… Once it had all been deleted I then had to run a REORG of all these table spaces and so now we come to part two of the BLOG…
REORGing the Directory
Firstly, if you are in Db2 13 you must Reorg the SPT01 and SYSLGRNX anyway to get the new DSSIZE 256GB activated. Secondly, Db2 is clever, so for certain table spaces, it will actually check the LOG to make sure you have taken a COPY:
“Before you run REORG on a catalog or directory table space, you must take an image copy. For the DSNDB06.SYSTSCPY catalog table space and the DSNDB01.DBD01 and DSNDB01.SYSDBDXA directory table spaces, REORG scans logs to verify that an image copy is available. If the scan of the logs does not find an image copy, Db2 requests archive logs.”
Db2 for z/OS Utility Guide and Reference “Before running REORG TABLESPACE”
Pretty clear there!
We are good to go as we only have the SPT01 and its LOBs. Here is an example Utility Syntax for doing the deed:
REORG TABLESPACE DSNDB01.SPT01
SHRLEVEL REFERENCE AUX YES
SORTDEVT SYSALLDA SORTNUM 3
COPYDDN (SYSC1001) Pretty simple as the AUX YES takes care of the LOBs. Remember to COPY all objects afterwards as well!
COPY TABLESPACE DSNDB01.SPT01
COPYDDN (SYSC1001)
FULL YES
SHRLEVEL REFERENCE
COPY TABLESPACE DSNDB01.SYSSPUXA
COPYDDN (SYSC1001)
FULL YES
SHRLEVEL REFERENCE
COPY TABLESPACE DSNDB01.SYSSPUXB
COPYDDN (SYSC1001)
FULL YES
SHRLEVEL REFERENCE
How many after?
Once these were all done, I looked back at the track usage:
The SPTR had 4,485 tracks (was 6,630)
The SYSSPTSEC_DATA had 7,575 tracks (was 13,929)
The SYSSPTSEC_EXPL had 4,635 tracks (was 6,357)
This is a total of 1,113 Cylinders (was 1,795) for 90,858 (was 118,553) rows of data.
This is very nice saving of 25% which was worth it for me!
Directory Tips & Tricks
Finally, a mix-n-match of all things Directory and Catalog.
Remember to always reorg the Directory and the Catalog table spaces in tandem.
Remember to always do a COPY before you do any reorgs!
FASTSWITCH YES is ignored for both Catalog and Directory reorgs.
Any more Limits?
Yep, you cannot REORG the DSNDB01.SYSUTILX at all. Only hope here is IDCAMS Delete and Define – dangerous!
LOG YES is required if SHRLEVEL NONE is specified for the catalog LOB table spaces.
If SHRLEVEL REFERENCE is specified, LOG NO must be specified.
The SORTDEVT and SORTNUM options are ignored for the following catalog and directory table spaces:
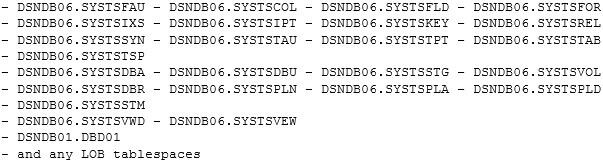
The COPYDDN and RECOVERYDDN options are valid for the preceding catalog and directory tables if SHRLEVEL REFERENCE is also specified.
Inline statistics with REORG TABLESPACE are not allowed on the following table spaces:

IBM now pack a complete Catalog and Directory REORG with the product to make it nice and easy to schedule and run! Look at member <your.db2.hlq>.SDSNSAMP(DSNTIJCV) for details.
To REORG or not to REORG?
This is the eternal question! For Db2 13 you must do at least two table space REORGs, as previously mentioned, but the hard and fast rule about the complete Db2 Catalog and Directory is: about once per year is normally sufficient. If you notice BIND/PREPARE times starting to go horribly wrong then a REORG is probably worth it, and it may be time to check the amount of COLGROUP statistics you have!
The recommendation from IBM is, “before a Catalog Migration or once every couple of years, and do more REORG INDEX than REORG TS.”
I am now keeping an eagle eye on my Db2 Directory LOBs!
If you have any Directory/Catalog Hints & Tips I would love to hear from you.
TTFN
Roy Boxwell

