

Hi all! This month, I would like to share some things that I have recently learned about Db2 for z/OS buffer pool management and tuning as there was some chatter on Listserv about the sizing of buffer pools.
It all started with some Freeware…
Well actually my freeware! SEG created a BPOOL check freeware program to do a quick analysis of your local and group buffer pools. This freeware you can download here is based upon the rules of our new SQL WorkloadExpert (WLX) Buffer pool Use Case where WLX checks and recommends changes to your buffer pools as well as generating the ALTERs you need.
Readers responded
What we saw, after looking at the responses, was *all* sites have buffer pool problems and are not even aware of them!
Bigger is Better!
Well, actually, no … Dan Luksetich and John Campbell had a conversation a few years ago about the topic of “When is too big too bad?” The basic rub of the matter was this:
“LRU chains (queues, whatever you want to call them) are initially allocated at 4,000 pages. For small pools, the chains are allocated as needed, up to 255 chains. Then once you are over 1,020,000 pages, the chains grow in size. At about 800GB to 1TB the user starts to see CPU go up as management of the longer chains becomes excessive. … In addition, if you have a very large pool, you’ll want to set VDWQT and DWQT very low. I have VDWQT at 0,128 for some large pools and others at 1%.”
One Big Pool Or …
So, if you had decided to get monolithic on your BP definitions, it might well be time to do a quick rethink and spread the load across multiple largish (up to 800 GB) buffer pools.
Do Not Forget the DWQTs!
We should not be forgetting to take care of DWQT and its vertical assistant, the VDWQT, with its two values – Just percentage of the buffer pool or, after a comma, an absolute number of pages going up to 9999. These two values are specifically designed for large buffer pools where 1% just doesn’t hack it as a trigger for deferred write. Imagine our example buffer pool before with 1,020,000 pages – 1% is still a huge 10,200 pages!
Why Do We Have Buffer Pools?
Remember, the point of buffer pools is to stop I/O and so trickling these updates out instead of hammering them out is definitely a good way forward!
Seeing is Believing!
Do a few -DISPLAY BUFFERPOOL(xxx) DETAIL(*) commands (obviously replacing xxx with your buffer pool of choice) and check out the counters in the DSNB421I message. If you also compute how long the buffer pool has been active, or you do two commands separated by a known amount of time ,you can then simply calculate /sec values. If you are getting more than 1 DWT HIT per second then it is time to act. Same is true for VERTICAL DWT HIT but you can afford to get more of these than the DWT HIT ones!
Groups are Good?
You always get a good feeling traveling in a group, and theoretically, it should be the same with GROUP BUFFERPOOLS, as these beasts control the buffer pool usage between members in a data-sharing system. Normally, they are set up and then simply forgotten about! After all, if all is working who cares?
How Does it Look?
Here’s the output of a post processed by me in Excel, -DIS GROUPBUFFERPOOL(*) TYPE(GCONN) GDETAIL(*) MDETAIL(*) command:
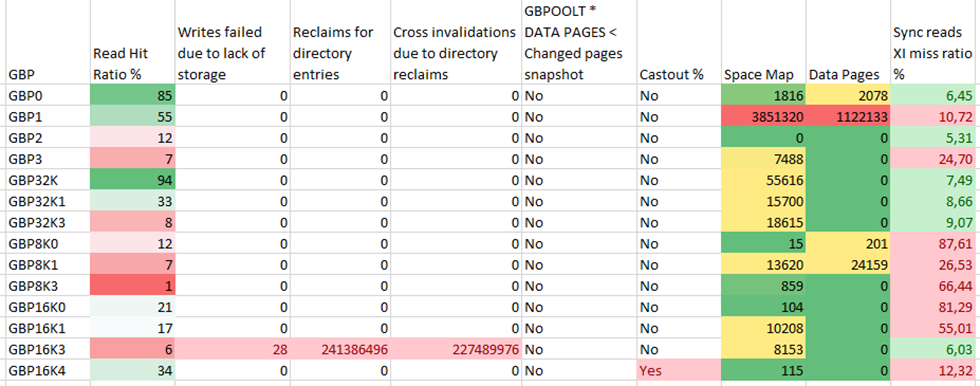
Not good!
We all know that the Read Hit Ratio % can basically be ignored at the group level so that’s ok.
But glance down at GBP16K3 – Storage problems, massive reclaims and cross invalidations aplenty. This group buffer pool *must* be examined under the microscope!
The Db2 Guru Says
John Campbell commented:
“It is possible that the reference to updated data across members is very low. But if the miss ratio is elevated across most of the GBPs this not a likely explanation. If check that there no directory entry reclaims causing XIs. These should be tuned away first ie increase INITSIZE and RATIO. Then go after tuning to reduce XI misses by increasing INITSIZE. In both cases rebuild of respective GBP will be required.”
Just the Facts Ma’am
In this case, the first thing is to ratify the RATIO and INITSIZE.
- Size of all local BPs for BP16K3 is 40,000 pages
- Current directory to data ratio is 10
- Allocated size is 65536, so 64 MB
- Number of directory entries is 30,771
- Number of data pages is 3,076
From this you can derive* that the starting size (INITSIZE) of GB16K3 should be increased to at least 89 MB, which then gives 44,445 Directory entries and 4,445 data pages.
Monitor Monitor Monitor
Once this change has been implemented the GBPs must be monitored to see if RATIO could/should be changed. Then check out that the Writes failed, Reclaims for directory and especially the Cross-Invalidation counters all go down!
A Little Tweak Can Work Wonders!
Buffer pool tuning is not new and will never go away, but you can get very good system-wide improvements with a few well aimed tweaks!
TTFN.
Roy Boxwell
* When I say “derive” what I meant is:
Add up all the Local BPs VPSIZE for each member -> A (directory entries)
Divide this number by the RATIO and round up -> B (data entries required for above directories)
Divide this number by the RATIO and round up -> C (directory entries)
Divide this number by the RATIO and round up -> D (data entries required for above directories)
Iterate until the value is less than RATIO and then use the value -> 1
Add *all* of the numbers A, B, C, D, E … to get total number of directory entries NNNNN
Multiply NNNNN by 430 (size of a directory entry) and then divide by 1048576 rounding up, to get the size of the Directory Entries OOOOO in MB
Divide NNNNN by the RATIO rounding up, to get the total number of Data Entries required, then multiply this by the Bufferpool size in K (4, 8, 16 or 32) and divide by 1024 rounding up to get the size of the Data Entries MMMMM in MB
Add MMMMM and OOOOO to get the recommended GBP starting size in MB.
Compare with DSNB758I ALLOCATED SIZE KB / 1024
Easy going, huh? 🙂